One of my favorite pastimes is tinkering with things in order to find out how to make them more efficient. In fact, self-improvement is so important to us here at Keybridge Web that it’s part of our core values in the form of Kaizen. There’s just a certain sense of accomplishment and bliss when you create something that just works.
That’s why — when I stumbled upon a certain family of Google Sheet functions — I was absolutely floored.
Once you get a knack for it, the ImportXML function makes you feel like a Google Sheets God. With this function, you can import data from almost any webpage, and even set parameters for the specific type of data that you want to collect.
So, how does it actually work? Essentially, ImportXML pulls data from a website using an element’s XPath as a key.
If you’re not super tech-savvy and you have no idea what that means, bear with me a little longer and it’ll begin to click. Just know that instead of mashing CTRL+C and CTRL+V ad nauseum trying to get the data you need, ImportXML can do all that heavy lifting for you.
Uses
The real beauty of the ImportXML function is that it has an inexhaustible number of uses. For example, we here at Keybridge Web use ImportXML to generate a weekly list of recent WordPress vulnerabilities from iThemes’s vulnerability reports.
But that’s just the tip of the iceberg. Once you get more comfortable messing around with ImportXML, you can use it to:
- Get a list of emails from a company’s team page
- Extract a site’s title tags and meta descriptions
- Find the current temperature of Washington, DC
- Grab Apple’s current stock price
Okay, enough exposition. Let’s get into the nitty gritty.
ImportXML Function Syntax
Like all functions in a spreadsheet, ImportXML has a specific syntax you need to follow in order for it to work:
=ImportXML(url, xpath_query)
The URL is just the link to the webpage (in quotes), and the xpath_query is the specific XPath you’d like to target (also in quotes).
As an example, let’s say you wanted to pull some sort of information from the Wikipedia page of George Washington. Step one would be to add the URL:
=ImportXML(“https://en.wikipedia.org/wiki/George_Washington”, xpath_query)
Next, you identify what kind of information you want, and then find it’s XPath.
Let’s say we want to get a list of all of the section headers on this Wikipedia page. First, find a section header on the page (I chose “Early life (1732–1752)”). Then, right click on the text, and click the “Inspect” button. This will open the Developer Tools view for Google Chrome.
You’ll see there’s a line of HTML highlighted in this new pane. Right click on it, go to “Copy” in the menu, and then hit “Copy full XPath.”
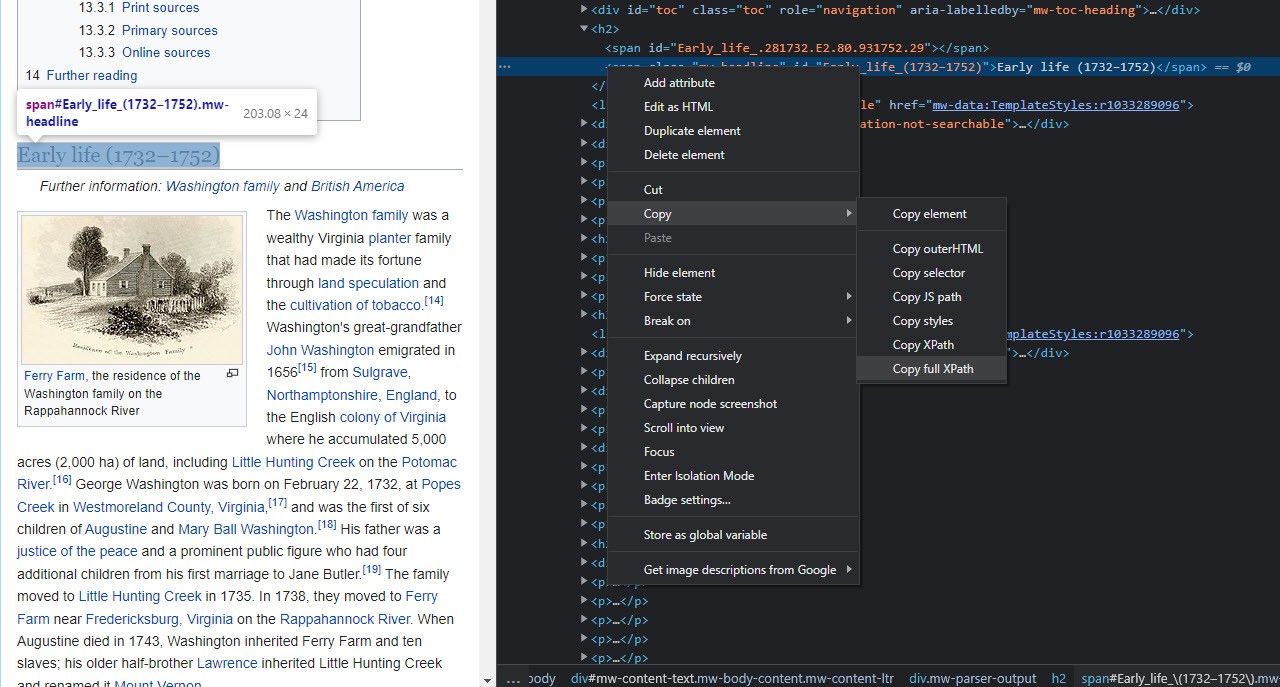
We’ll want to paste this into our formula now. When you do, put quotes around it, and add one additional forward slash (“/”) after the first quotation mark. Your formula should look like this, then:
=ImportXML(“https://en.wikipedia.org/wiki/George_Washington”, “//html/body/div[3]/div[3]/div[5]/div[1]/h2[1]/span[2]”)
Once you add that in your spreadsheet, the formula will spit out: “Early life (1732–1752).”

Now, what about the rest of the section headers? Well, to get those, we’ll need to edit our xpath_query a little.
You see those numbers in the XPath? Those are telling the formula which content on the web page to look for. So, “h2[1]” means that it’s looking for the first instance of an H2 header tag. In the developer view in Chrome, you can see all of the different types of HTML tags used on the webpage. They’re labelled with < and > symbols (e.g. <h2> and </h2>).
So, if you delete the [1] from h2[1], you’re essentially telling your formula to look for any and all instances of an H2 header tag, instead of just the first one. Let’s also take out the “[2]” from that “span[2]” at the end, to avoid any potential issues.
If you change your formula to the following, then:
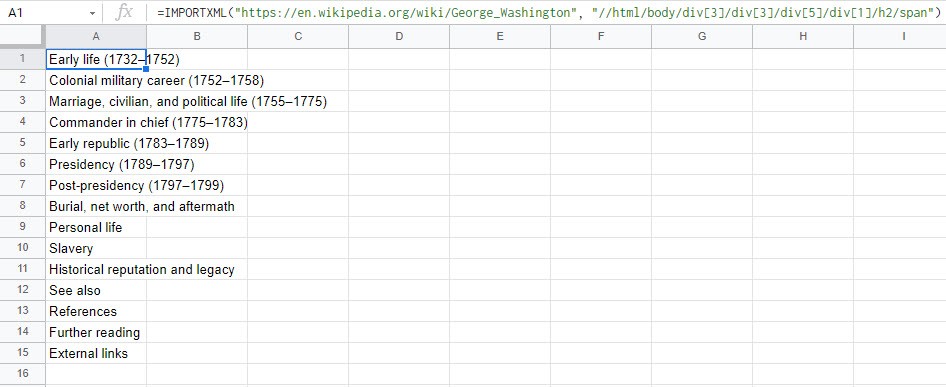
=ImportXML(“https://en.wikipedia.org/wiki/George_Washington”, “//html/body/div[3]/div[3]/div[5]/div[1]/h2/span”)
The formula will pull all of the section headers from the Wikipedia page. And look at that, all of George Washington’s life at a glance.
And, once you combine ImportXML with some of the other functions in Google Sheets and you do a little more digging into how XPaths work, you can become a truly unstoppable web scraper.
If you’re looking to really beef up your arsenal, then I’d suggest looking into ImportXML’s siblings: ImportDATA, ImportRANGE, ImportHTML, and ImportFEED. You can find more information about them in Google’s support documentation. Best of luck in your future spreadsheeting endeavors!
Want to learn more about how data collection can help you and your business? Contact us today to find out!
